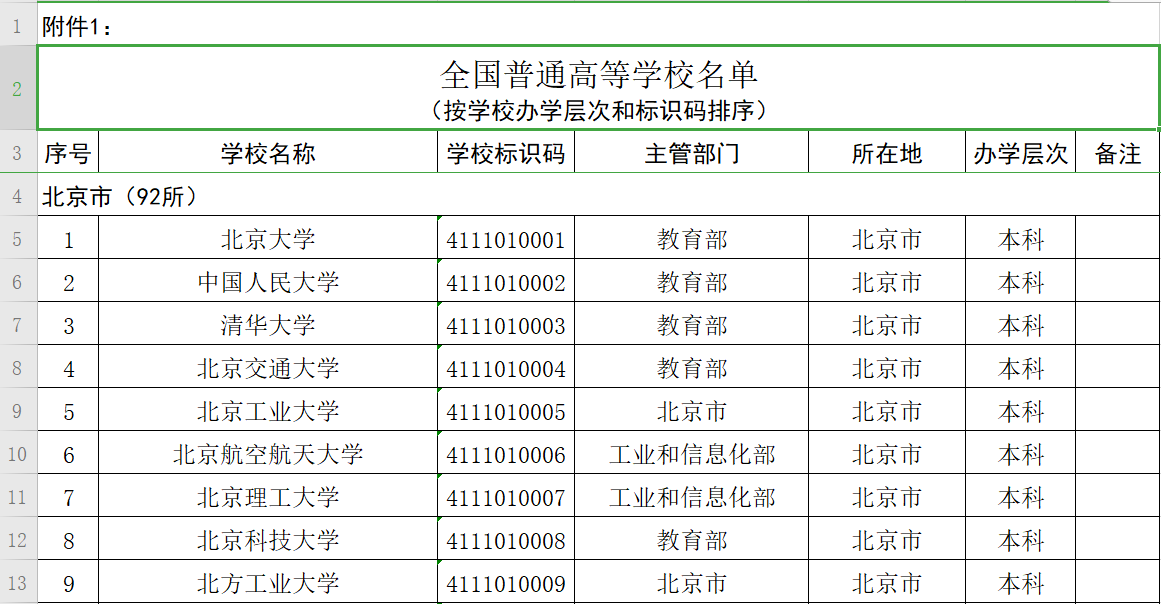
1.去教育部官网下载excel数据:http://www.moe.gov.cn/srcsite/A03/moe_634/201706/W020170616379651135432.xls
2.把xls数据转换成json格式
[root@do1_qy_10479 opt]# cat just4json.py# encoding: utf-8import xlrdfrom collections import OrderedDictimport jsonimport codecswb = xlrd.open_workbook('aa.xls')convert_list = []#sh ==> sheetsh = wb.sheet_by_index(0)title = sh.row_values(2)for rownum in range(4,sh.nrows): rowvalue = sh.row_values(rownum) single = OrderedDict() for colnum in range(0,len(rowvalue)): print(title[colnum],rowvalue[colnum]) single[title[colnum]] = rowvalue[colnum] convert_list.append(single)j = json.dumps(convert_list,ensure_ascii=False)with codecs.open('tojson.json',"w","utf-8") as f: f.write(j) 3.得到的json数据
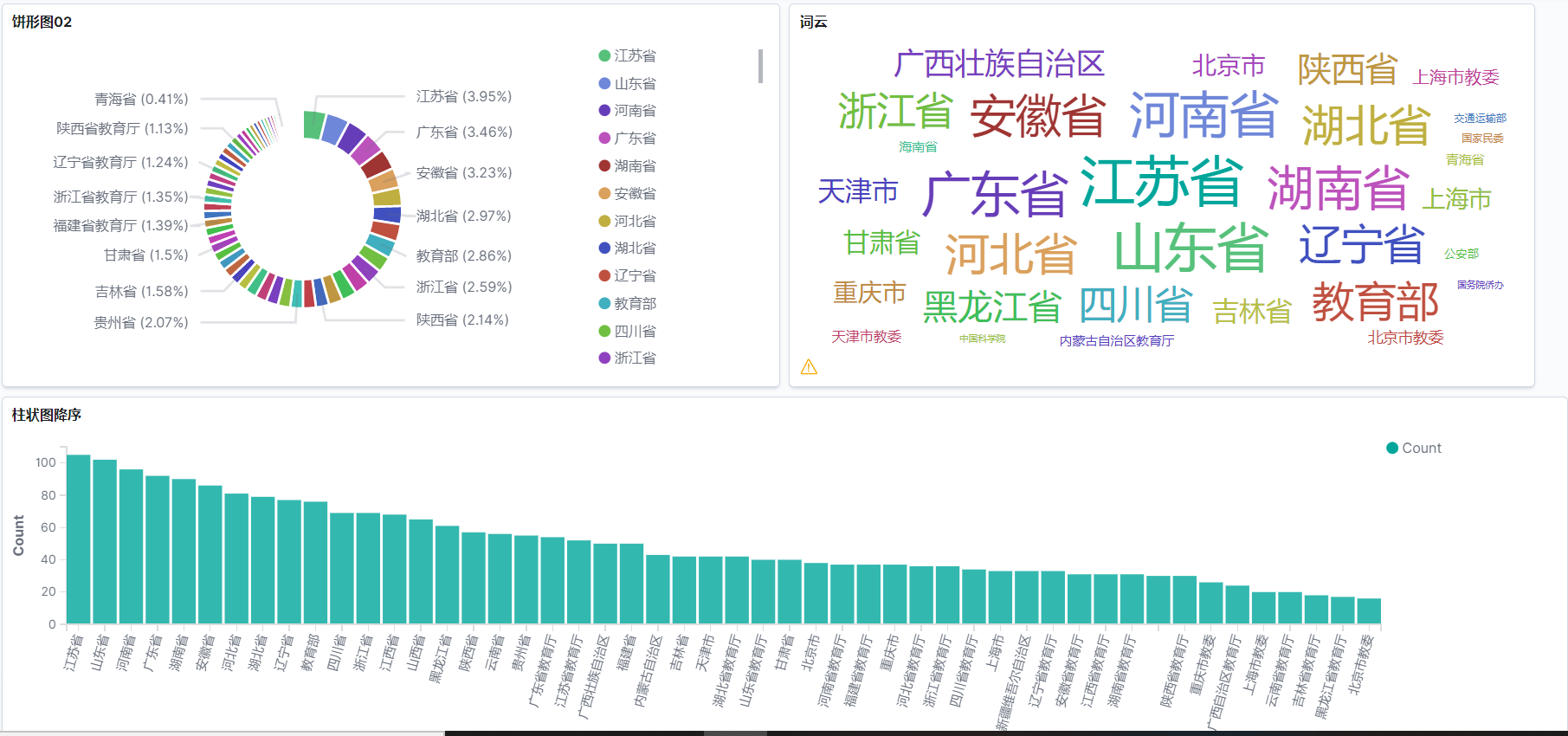
[{ "rowid": 2631.0, "name": "新疆工业职业技术学院", "code": "4265051060", "charge": "新疆维吾尔自治区", "location": "乌鲁木齐市", "level": "专科", "remark": ""}] 4.把json格式的数据倒进elastic search
#python 3.6# -*- coding:utf-8 -*-__author__ = 'BH8ANK'import jsonimport os#文件预处理a = open(r"/opt/englishjson.json", "r",encoding='UTF-8')out = a.read()tmp = json.dumps(out)tmp = json.loads(out)#构造curl语句上传数据num = len(tmp)i = 0while i < num: data = json.dumps(tmp[i],ensure_ascii=False) i = str(i) curl_word_1 = """ curl -XPUT "http://172.31.250.16:9200/daxue04/_doc/""" + i #此处设置ES的IP:PORT curl_word_2 = '''" -H 'Content-Type: application/json' -d''' curl_word_3 = "'" + data + "'" curl_words = curl_word_1 + curl_word_2 + curl_word_3 os.system(curl_words) print(curl_words) i = int(i) i = i + 1
5.查询es的数据
GET daxue05/_doc/0{ "_index" : "daxue05", "_type" : "_doc", "_id" : "0", "_version" : 1, "_seq_no" : 0, "_primary_term" : 1, "found" : true, "_source" : { "rowid" : 1.0, "name" : "北京大学", "code" : "4111010001", "charge" : "教育部", "location" : "北京市", "level" : "本科", "remark" : "" }} 6.参考:
7.